Тестування чорної скриньки
Тестування чорної скриньки базується на специфікаціях і одержує тести з зовнішньої документації щодо об’єкта тестування. Основна мета тестування чорної скриньки — перевірити поведінку системи на відповідність її специфікаціям. Тому в англомовній літературі можна зустріти термін specification-based (той що базується на специфікації), який є синонімом black-box.
Функціональне та нефункціональне
Функціональне тестування оцінює функції, які повинен виконувати компонент або система. Функції – це «те, що» повинен робити тестовий об’єкт. Основною метою функціонального тестування є перевірка функціональної повноти, функціональної правильності та функціональної відповідності.
Нефункціональне тестування оцінює атрибути, відмінні від функціональних характеристик компонента або системи. Нефункціональне тестування — це перевірка того, «наскільки добре поводиться система». Основною метою нефункціонального тестування є перевірка нефункціональних характеристик якості програмного забезпечення.
Стандарт ISO/IEC 25010 надає таку класифікацію нефункціональних характеристик якості програмного забезпечення:
- Ефективність виконання/продуктивності (Performance efficiency)
- Сумісність (Compatibility)
- Зручність використання (Usability)
- Надійність (Reliability)
- Безпека (Security)
- Зручність супроводу (Maintainability)
- Портативність (Portability)
Іноді нефункціональне тестування доцільно розпочинати на ранніх стадіях життєвого циклу (наприклад, як частину перевірки та тестування компонентів або тестування системи).
Багато нефункціональних тестів є похідними від функціональних тестів, оскільки вони використовують ті самі функціональні тести, але перевіряють, що під час виконання функції виконується нефункціональне обмеження (наприклад, перевірка того, що функція виконується протягом заданого часу). Пізнє виявлення нефункціональних дефектів може становити серйозну загрозу для успіху проєкту.
Функціональне тестування
Функціональне тестування системи включає тести, які оцінюють функції, які система повинна виконувати. Функціональні вимоги можуть бути описані в робочих продуктах, таких як специфікації бізнес-вимог, епіки, історії користувачів, варіанти використання або функціональні специфікації, або вони можуть бути незадокументованими. Функції – це «те, що» повинна робити система.
Функціональні тести слід виконувати на всіх рівнях тестування (наприклад, тести для компонентів можуть базуватися на специфікації компонентів), хоча фокус на кожному рівні різний.
Функціональне тестування розглядає поведінку програмного забезпечення, тому методи чорної скриньки можуть бути використані для отримання умов тестування та тестових випадків для функціональності компонента чи системи.
Ретельність функціонального тестування можна виміряти за допомогою функціонального покриття. Функціональне покриття – це ступінь, до якого певна функціональність була покрита тестами, і виражається у відсотках від типу(ів) покритого елемента.
Наприклад, використовуючи відстежуваність між тестами та функціональними вимогами, можна розрахувати відсоток цих вимог, які покриваються тестами, потенційно виявивши прогалини в покритті.
Розробка та виконання функціональних тестів може вимагати спеціальних навичок або знань, таких як знання конкретної бізнес-проблеми, яку вирішує програмне забезпечення.
Usability і функціональне
Зручність використання (Usability) є нефункціональною характеристикою. І відповідно тестування зручності використання (Usability testing) є нефункціональним типом тестування.
Однак в ряді випадків можна побачити, що до функціонального тестування відносять тестування базової зручності використання (Basic usability testing) чи тестування базового чи мінімально необхідного інтерфейсу користувача (Basic user interface testing).
Більш коректним є другий варіант (про базовий інтерфейс). Тим не менше важко провести межу між базовим інтерфейсом та зручністю використання. Низка авторів відносить тестування інтерфейсу користувача (user interface testing) до функціонального тестування. Однак під час тестування зручності використання також оцінюється робота користувацького інтерфейсу. Якщо в ході тестування нас цікавить працездатність, функціональність елементів інтерфейсу, то можна вважати таке тестування функціональним. Якщо ж нас цікавить питання оптимальності розміщення елементів інтерфейсу, їхня доступність, читабельність шрифтів тощо, то це вже парафія Usability тестування.
Процес виконання функціонального тестування
- Зрозуміти функціональні вимоги
- Визначити тестові вхідні дані
- Визначити очікувані результати
- Виконати тестові кейси
- Порівняти фактичні та очікувані результати
Класи еквівалентності
Поділ на класи еквівалентності ділить дані на розділи таким чином, щоб усі члени певного розділу оброблялися однаково. Існують розділи еквівалентності як для дійсних, так і для недійсних значень.
Дійсні значення – це значення, які повинні бути прийняті компонентом або системою. Розділ еквівалентності, що містить дійсні значення, називається «дійсним розділом еквівалентності».
Недійсні значення – це значення, які повинні бути відхилені компонентом або системою. Розділ еквівалентності, що містить недійсні значення, називається «недійсним розділом еквівалентності».
Розділи можна ідентифікувати для будь-якого елемента даних, пов’язаного з тестовим об’єктом, включаючи входи, виходи, внутрішні значення, значення, пов’язані з часом (наприклад, до або після події), а також для параметрів інтерфейсу.
Кожне значення має належати одному й лише одному розділу еквівалентності.
Якщо в тестових випадках використовуються недійсні розділи еквівалентності, їх слід тестувати окремо, тобто не поєднувати з іншими недійсними розділами еквівалентності, щоб гарантувати, що помилки не маскуються. Збої можуть бути замасковані, коли кілька збоїв відбуваються одночасно.
Щоб досягти 100% охоплення за допомогою цієї техніки, тестові випадки повинні охоплювати всі визначені розділи (включаючи недійсні розділи), використовуючи принаймні одне значення з кожного розділу. Покриття вимірюється як кількість розділів еквівалентності, перевірених принаймні одним значенням, поділена на загальну кількість визначених розділів еквівалентності, зазвичай виражену у відсотках. Поділ еквівалентності може застосовуватися на всіх рівнях тестування.

Аналіз граничних значень
Аналіз граничних значень (BVA) є розширенням розподілу еквівалентності, але його можна використовувати лише тоді, коли розділ впорядкований і складається з числових або послідовних даних. Мінімальне та максимальне значення (або перше та останнє значення) розділу є його граничними значеннями.
Наприклад, припустімо, що поле введення приймає одне ціле значення як вхід, використовуючи клавіатуру для обмеження введення таким чином, щоб інші варіанти були неможливі. Допустимий діапазон – від 1 до 5 включно. Отже, є три розділи еквівалентності: недійсний (занадто низький); дійсний; недійсний (занадто високий). Для дійсного розділу еквівалентності граничними значеннями є 1 і 5. Для недійсного (занадто високого) розділу граничне значення дорівнює 6. Для недійсного (занадто низького) розділу існує лише одне граничне значення, 0, оскільки це розділ лише з одним членом.
У наведеному прикладі ми визначаємо два граничні значення на межу. Межа між недійсним (занадто низьким) і дійсним дає тестові значення 0 і 1. Межа між дійсним і недійсним (занадто високим) дає тестові значення 5 і 6. Деякі варіанти цього методу визначають три граничні значення на межу: значення перед, на та безпосередньо за межею. У попередньому прикладі з використанням трьохточкових граничних значень нижні граничні тестові значення становлять 0, 1 і 2, а верхні граничні тестові значення – 4, 5 і 6.
Поведінка на межах розділів еквівалентності, швидше за все, буде неправильною, ніж поведінка всередині розділів. Важливо пам’ятати, що як визначені, так і впроваджені межі можуть бути зміщені вище або нижче запланованих положень, можуть бути взагалі опущені або можуть бути доповнені небажаними додатковими межами. Аналіз і тестування граничних значень виявлять майже всі такі дефекти, змушуючи програмне забезпечення показувати поведінку з розділу, відмінного від того, до якого має належати граничне значення.
Аналіз граничних значень можна застосовувати на всіх рівнях тестування. Ця техніка зазвичай використовується для перевірки вимог, які вимагають діапазону чисел (включаючи дати та час). Граничне покриття для розділу вимірюється як кількість протестованих граничних значень, поділена на загальну кількість визначених граничних тестових значень, зазвичай виражених у відсотках.

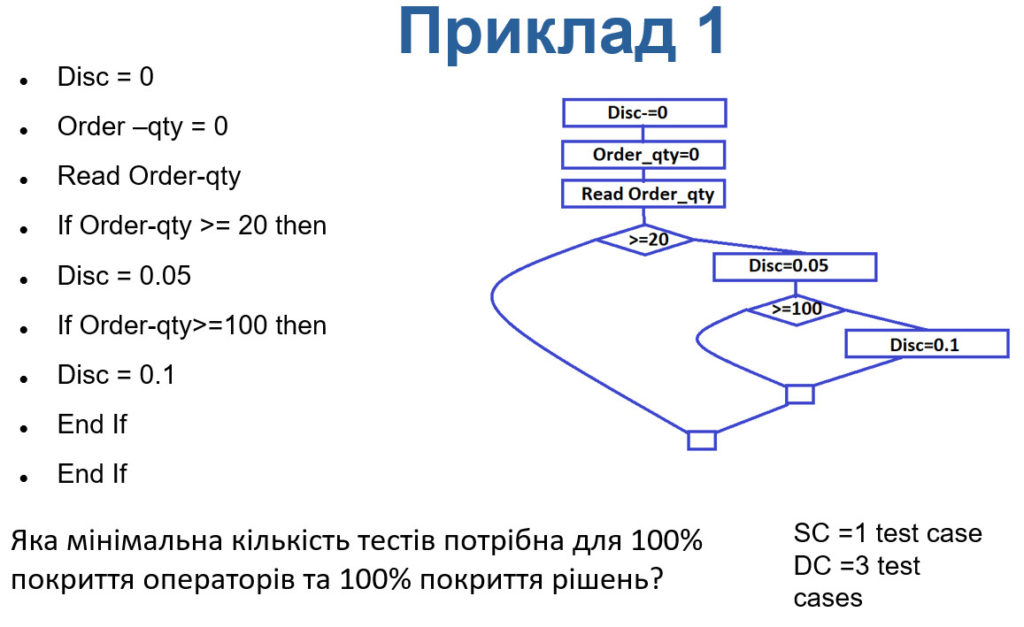
Приклад 1

В цьому прикладі у нас 5 класів еквівалентності: до 10 грамів, від 11 до 50 грамів, від 51 до 75 грамів, від 76 до 100 грамів та більше 100 грамів. Себто відповіді А та С не підходять оскільки містять лише 4 класи. Відповідь D є неправильною оскільки не тестує 5 клас. А правильна відповідь В.
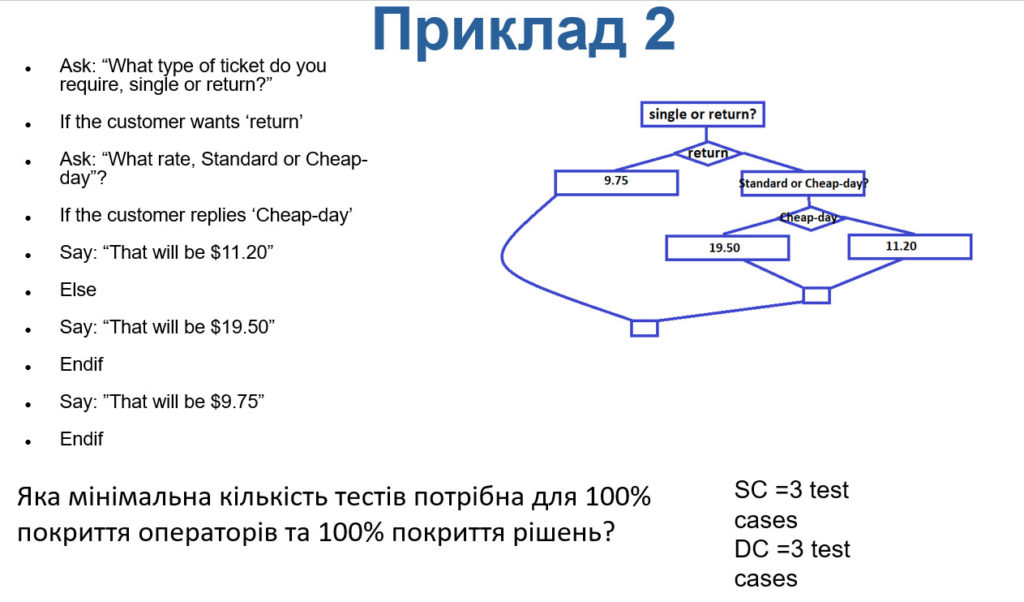
Приклад 2

Правильна відповідь в даному прикладі 33501 (4000+1500+28000).
Тестування таблиці рішень
Таблиці рішень є хорошим способом запису складних бізнес-правил, які система повинна реалізувати. Створюючи таблиці рішень, тестувальник визначає умови (часто входи) і кінцеві дії (часто виходи) системи. Вони утворюють рядки таблиці, зазвичай з умовами вгорі та діями внизу. Кожен стовпець відповідає правилу прийняття рішень, яке визначає унікальну комбінацію умов, що призводить до виконання дій, пов’язаних із цим правилом. Значення умов і дій зазвичай відображаються як логічні значення (істина чи хибність) або дискретні значення (наприклад, червоний, зелений, синій), але також можуть бути числами чи діапазонами чисел. Ці різні типи умов і дій розміщуються в одній таблиці.
Загальні позначення в таблицях рішень такі:
Для умов:
- Y означає, що умова виконується (також може відображатися як T або 1)
- N означає, що умова хибна (також може відображатися як F або 0)
- — означає, що значення умови не має значення (також може відображатися як N/A)
Для дій:
- lX означає, що дія має відбутися (також може відображатися як Y, T або 1)
- Порожнє означає, що дія не повинна відбуватися (також може відображатися як – або N, або F, або 0)
Повна таблиця рішень містить достатню кількість стовпців (тестових випадків), щоб охопити кожну комбінацію умов. Видаляючи стовпці, які не впливають на результат, можна значно зменшити кількість тестів. Наприклад, видаливши неможливі комбінації умов.
Загальний мінімальний стандарт охоплення для тестування таблиці рішень полягає в наявності принаймні одного тестового випадку на правило прийняття рішень у таблиці. Зазвичай це передбачає охоплення всіх комбінацій умов. Покриття вимірюється як кількість правил прийняття рішень, перевірених принаймні одним тестовим випадком, поділена на загальну кількість правил прийняття рішень, зазвичай виражених у відсотках.
Сильна сторона тестування таблиці рішень полягає в тому, що воно допомагає визначити всі важливі комбінації умов, деякі з яких інакше можна було б проігнорувати. Це також допомагає знайти прогалини у вимогах. Його можна застосовувати до всіх ситуацій, у яких поведінка програмного забезпечення залежить від комбінації умов, на будь-якому рівні тестування.
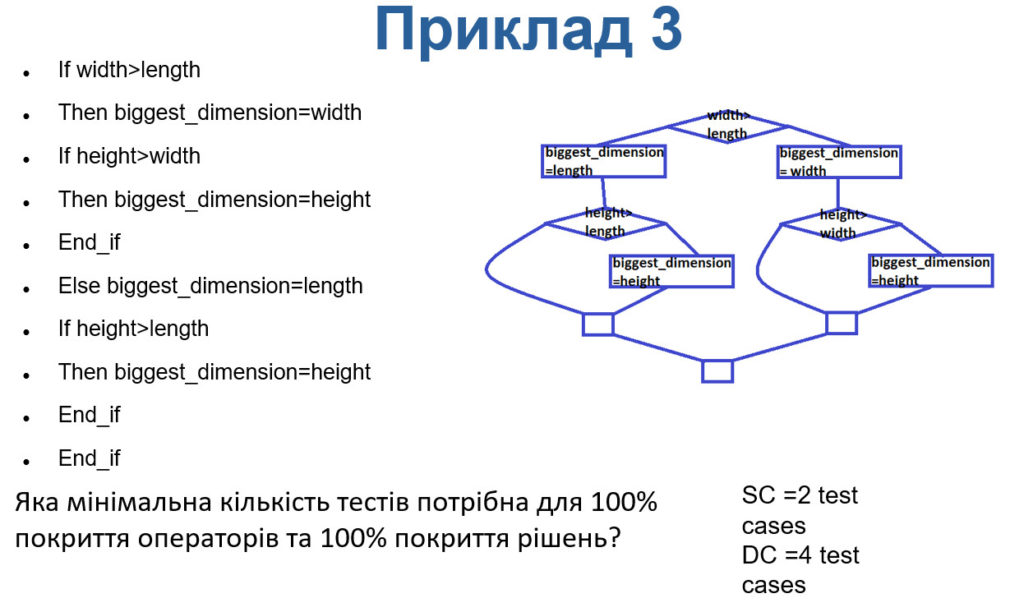
Приклад 3
Правила роботи:
- Кредит не надається безробітним
- Кредит надається особам, які мають постійну легальну роботу без обмежень
Вікові правила:
- Особам до 18 років кредит не надається
- Цільовою групою для отримання кредиту є люди 18-40 років
- Для осіб старше 40 років кредит не надається
Правила по доходу:
- Кредит не надається людям з доходом менше 1000 доларів США на місяць
- Кредит надається особам з доходом 1000-5000 USD/місяць, сума кредиту < 2000 USD
- Кредит надається людям з доходом понад 5000 доларів США на місяць, сума кредиту > 2000 доларів США
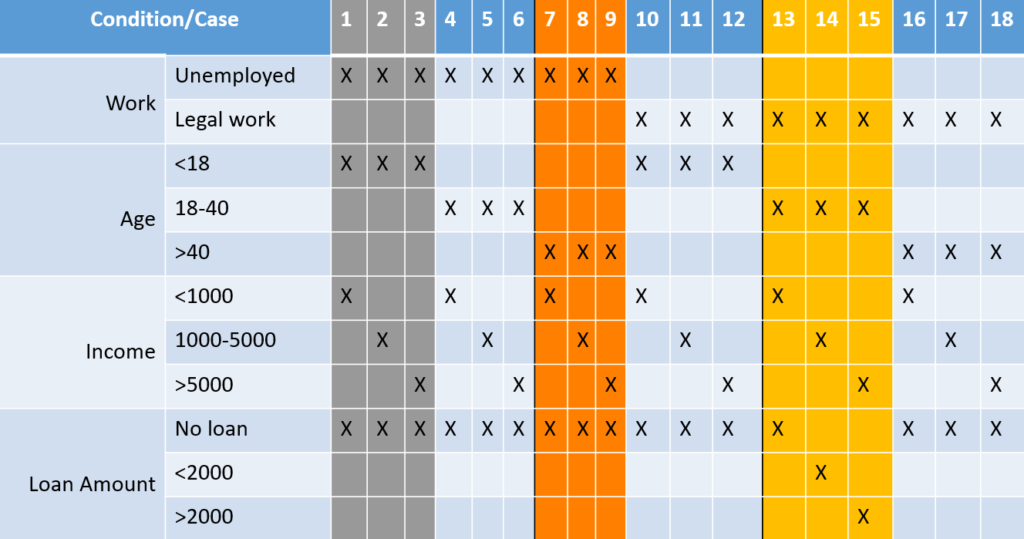
Спробуйте визначити очікуваний результат для наступних тест кейсів:
- Student, unemployed, 17 years old, income is 100 USD/month
- Post graduate, unemployed, 25 years old, no income
- Retired, unemployed, 60 years old, income is 200 USD/month
- Manager, legally employed, 50 years old, income 1500 USD/month
- Lawyer, legally employed, 45 years old, income 5000 USD/month
- Worker, legally employed, 35 years old, income 950 USD/month
- Accountant, legally employed, 28 years old, income 2500 USD/month
- Sales manager, legally employed, 37 years old, income 4500 USD/month
Тестування переходу стану
Компоненти або системи можуть по-різному реагувати на подію залежно від поточних умов або попередньої історії (наприклад, подій, які відбулися після ініціалізації системи). Попередню історію можна підсумувати за допомогою поняття станів. Діаграма переходу станів показує можливі стани програмного забезпечення, а також те, як програмне забезпечення входить, виходить і переходить між станами. Перехід ініціюється подією (наприклад, введення користувачем значення в поле). Результатом події є перехід. Та сама подія може призвести до двох або більше різних переходів з одного стану. Зміна стану може призвести до того, що програмне забезпечення виконає певну дію (наприклад, виведе обчислення або повідомлення про помилку).
Таблиця переходів станів показує всі дійсні переходи та потенційно недійсні переходи між станами, а також події та результуючі дії для дійсних переходів. Діаграми переходів станів зазвичай показують лише дійсні переходи та виключають недійсні переходи.
Тести можуть бути розроблені для покриття типової послідовності станів, для виконання всіх станів, для виконання кожного переходу, для виконання конкретних послідовностей переходів або для перевірки недійсних переходів.
Тестування переходу стану використовується для програм на основі меню та широко використовується в галузі вбудованого програмного забезпечення. Техніка також підходить для моделювання бізнес-сценарію з певними станами або для тестування екранної навігації. Концепція стану є абстрактною – вона може представляти кілька рядків коду або цілий бізнес-процес.
Покриття зазвичай вимірюється як кількість ідентифікованих станів або переходів, що перевіряються, поділена на загальну кількість ідентифікованих станів або переходів у тестовому об’єкті, зазвичай виражену у відсотках.
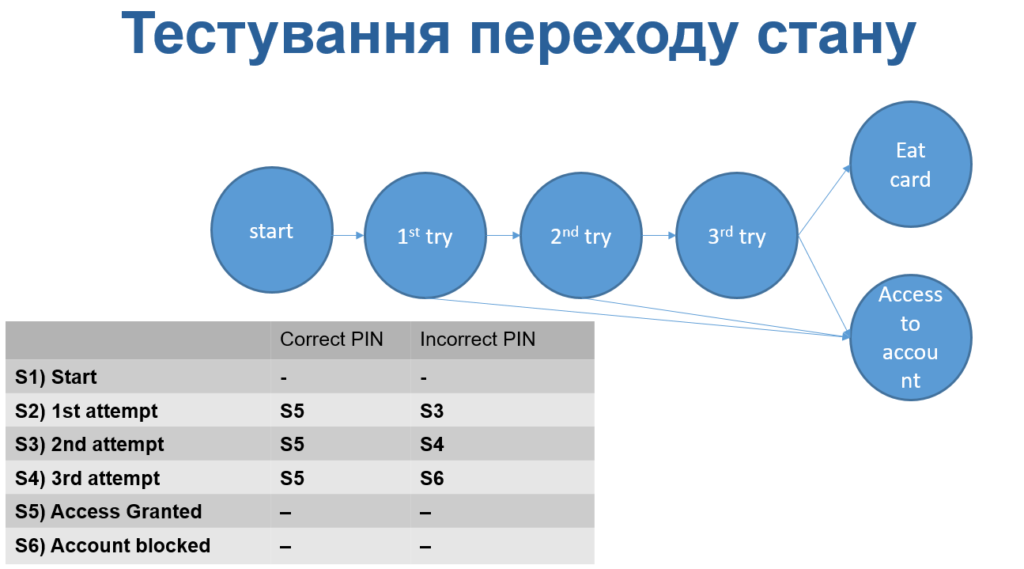
Відомий приклад-ілюстрація для демонстрації переходу станів. В даному випадку для покриття всіх станів знадобиться 2 тест кейси. А для покриття всіх дійсних переходів – 4 тест кейси.
Тестування варіантів використання
Тести можуть бути розроблені на основі варіантів використання, які є особливим способом проєктування взаємодії з елементами програмного забезпечення. Вони містять вимоги до програмних функцій. Варіанти використання пов’язані з виконавцями (користувачами, зовнішнім апаратним забезпеченням або іншими компонентами чи системами) і суб’єктами (компонентом або системою, до якої застосовано варіант використання).
Кожен варіант використання визначає певну поведінку, яку суб’єкт може виконувати у співпраці з одним або кількома виконавцями (UML 2.5.1 2017). Випадок використання може бути описаний взаємодіями та діями, а також передумовами, постумовами та звичайною мовою, де це доречно. Взаємодія між виконавцями та суб’єктом може призвести до змін стану суб’єкта. Взаємодії можуть бути представлені графічно за допомогою робочих процесів, діаграм діяльності або моделей бізнес-процесів.
Варіант використання може включати можливі варіації його базової поведінки, включаючи реакцію на виключення та обробку помилок (відповідь системи та відновлення після помилок програмування чи збоїв програми). Тести призначені для перевірки визначеної поведінки (основної, альтернативної та обробки помилок). Покриття можна виміряти кількістю протестованих варіантів використання, розділеною на загальну кількість варіантів поведінки, зазвичай виражається у відсотках.
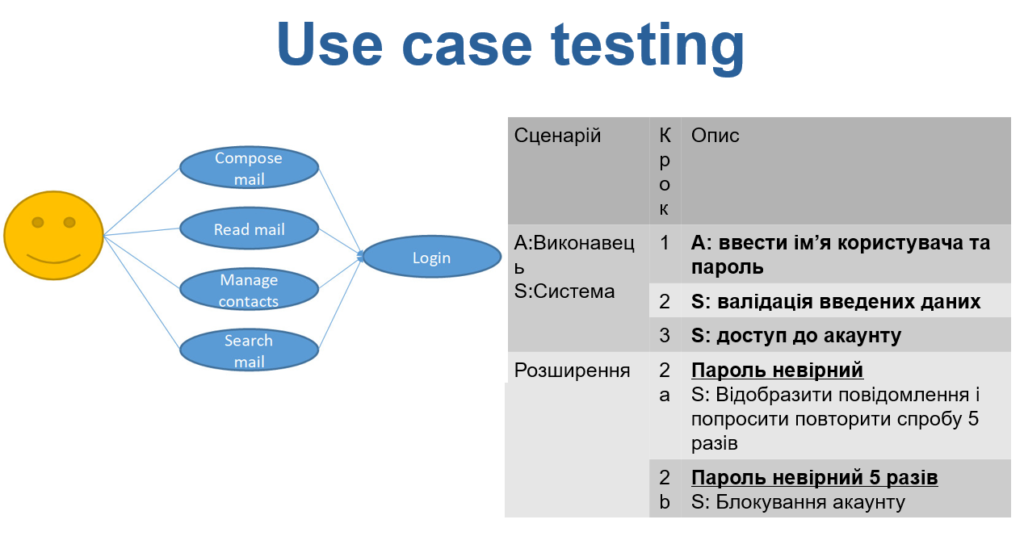
Приклад UML діаграми та сценарію використання логіну.
В цьому відео поговоримо про функціональне тестування:
00:00:03 Тестування чорної скриньки
00:03:20 Функціональне та нефункціональне тестування
00:05:58 Функціональне тестування
00:13:19 Usability і функціональне тестування
00:19:20 Процес виконання функціонального тестування
00:19:47 Техніка розподілу на класи еквівалентності
00:23:33 Техніка аналізу граничних значень
00:46:50 Техніка тестування таблиці рішень
01:08:35 Тестування переходу стану
01:15:33 Тестування варіантів використання